BIOLOGÍA Y GEOLOGÍA
BASE MOLECULAR DE LA VIDA
5. ÁCIDOS NUCLEICOS
5.1. ÁCIDOS NUCLEICOS
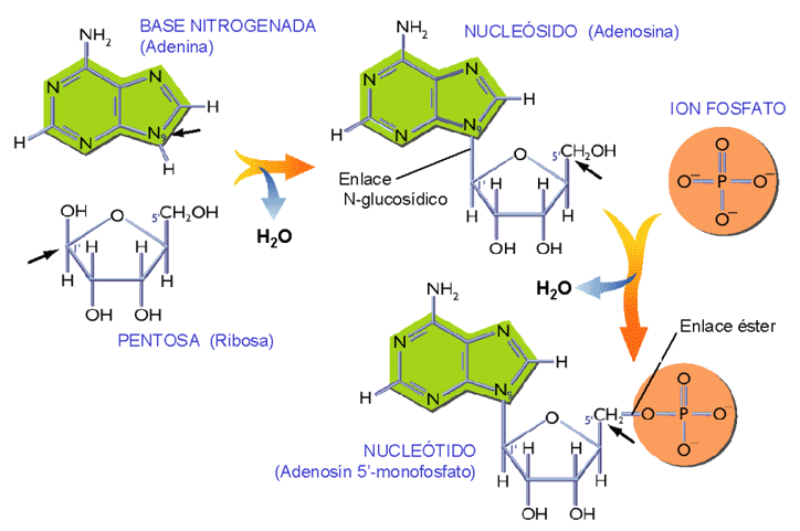
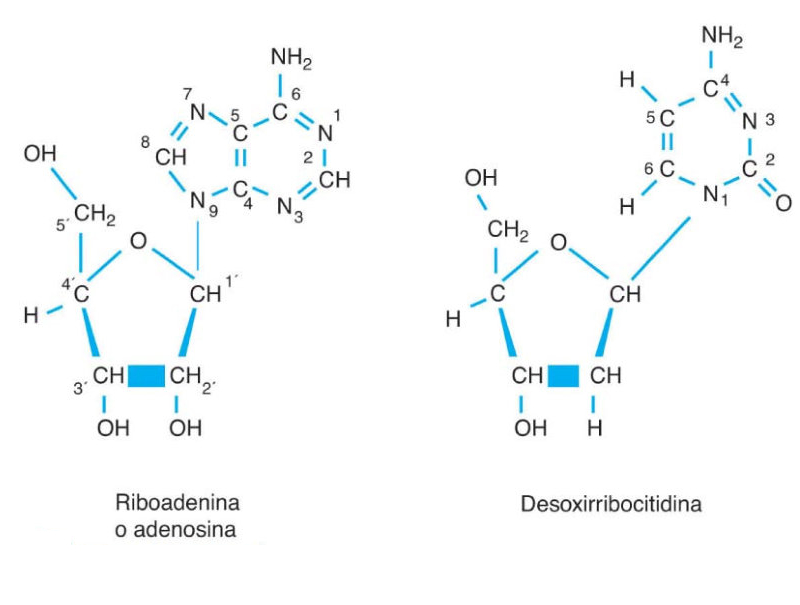
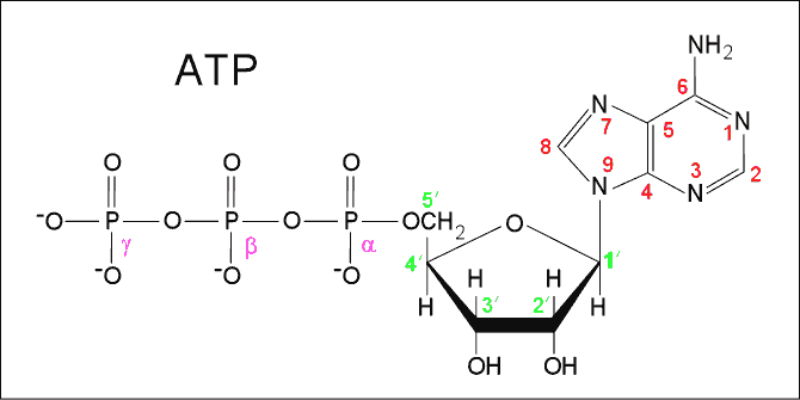
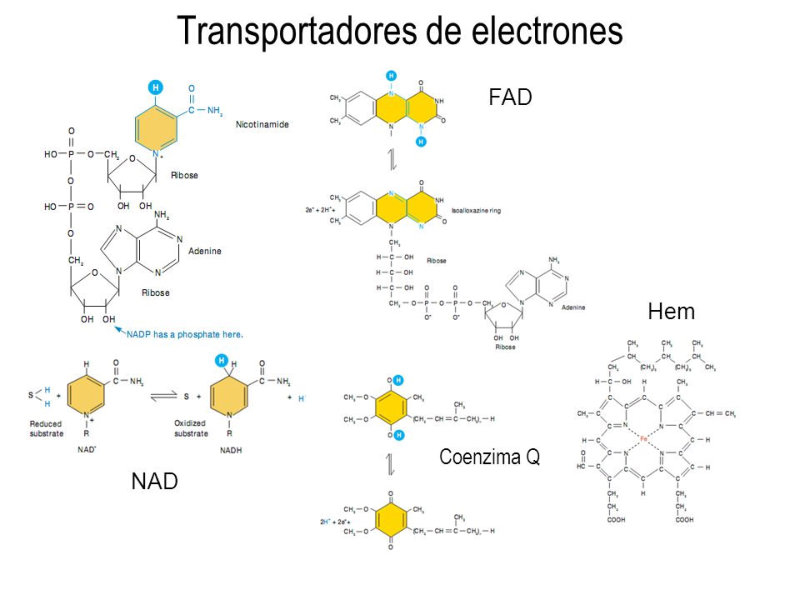
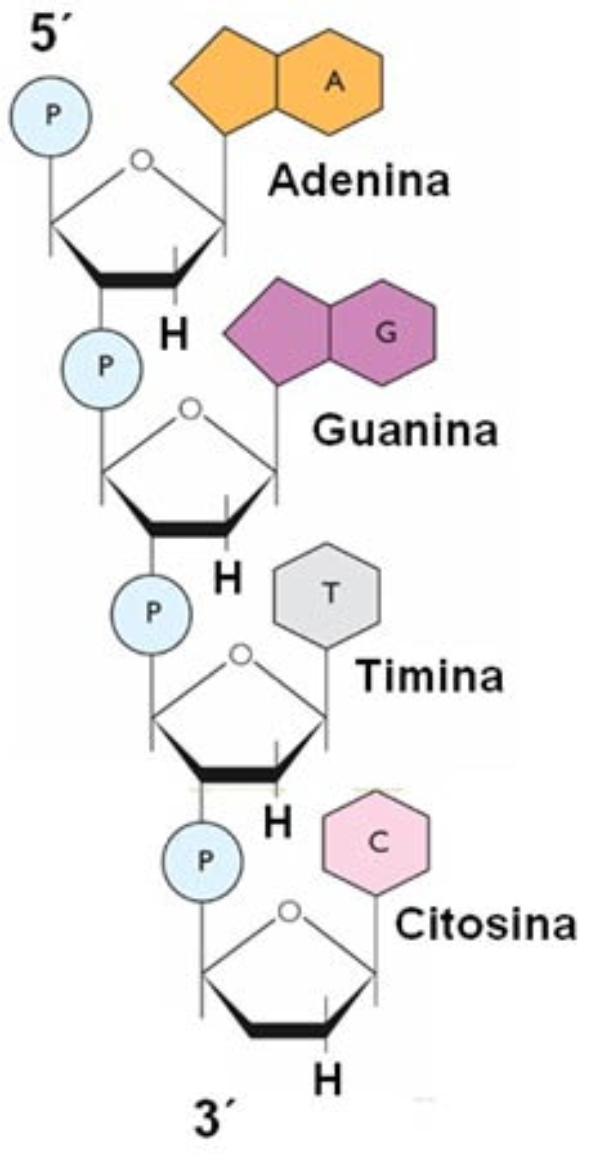
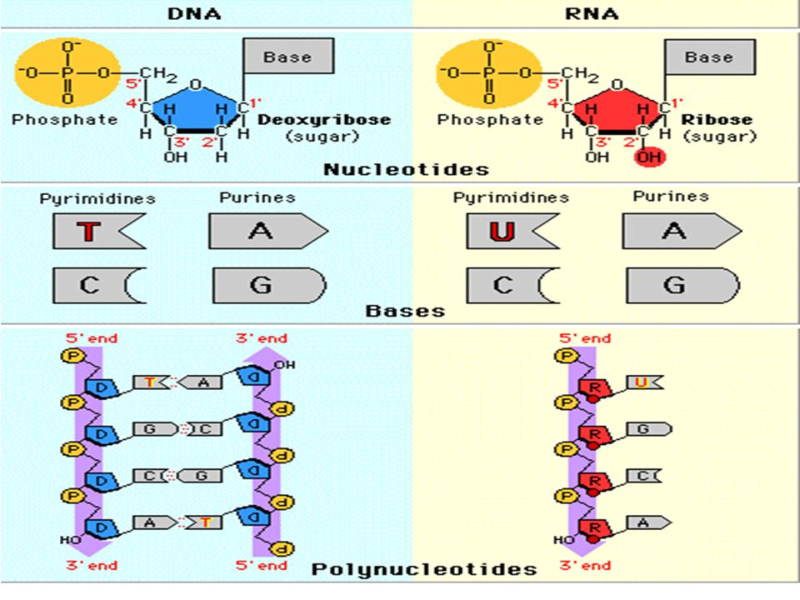
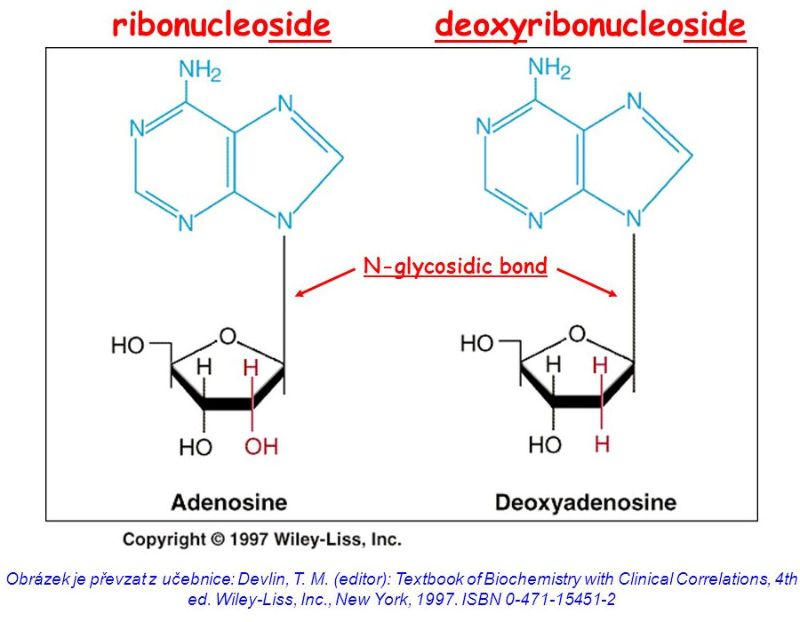
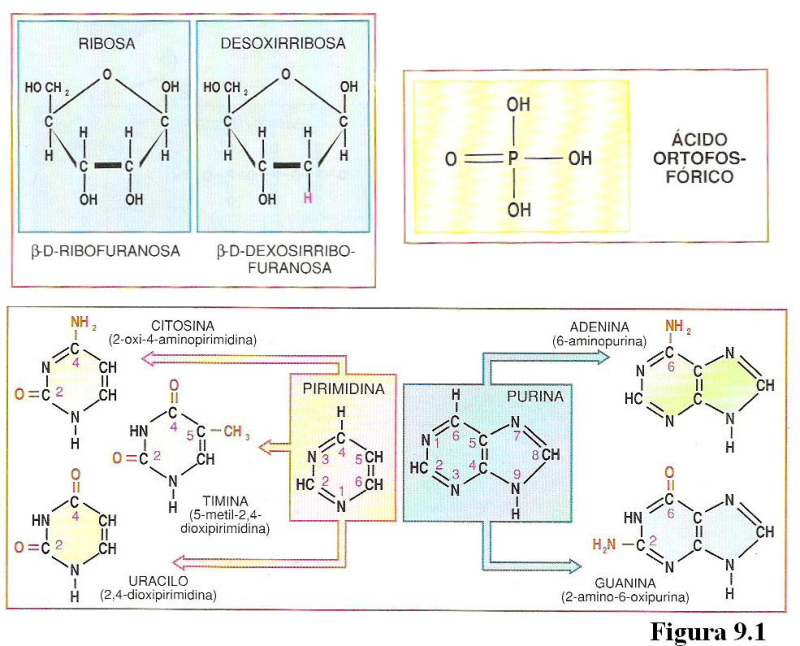
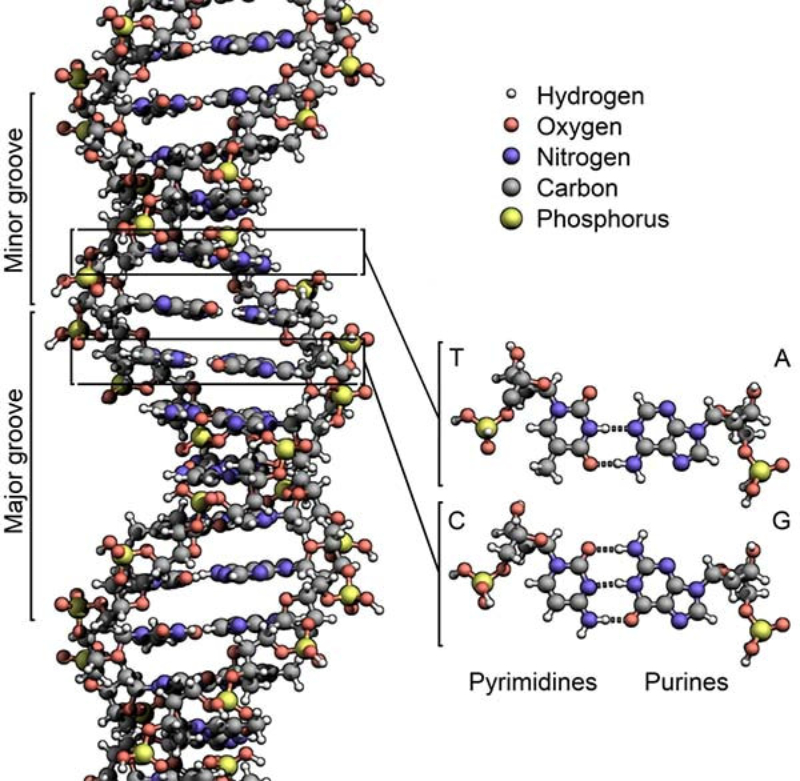
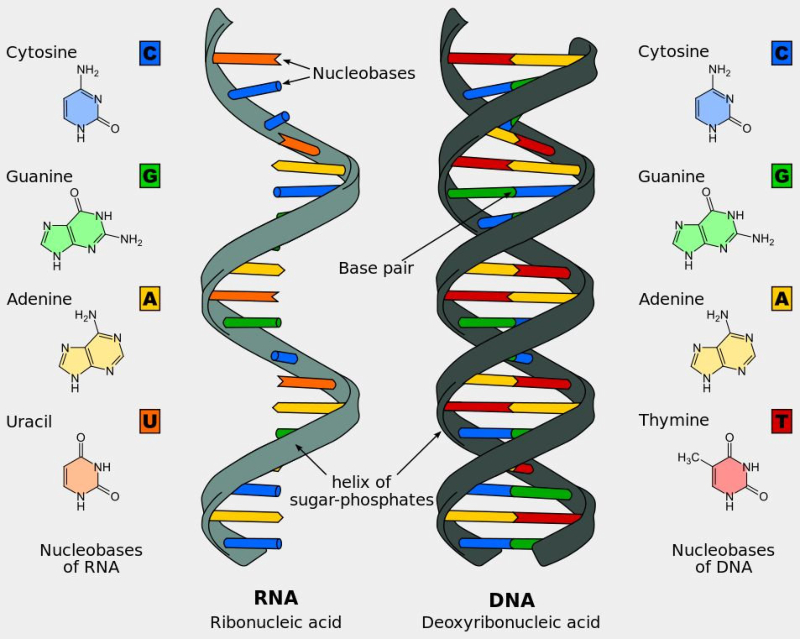
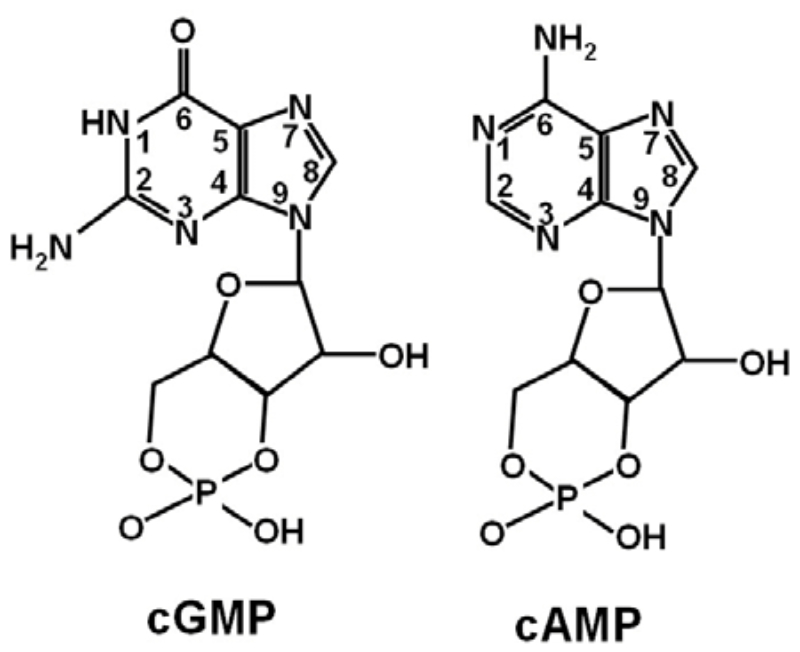
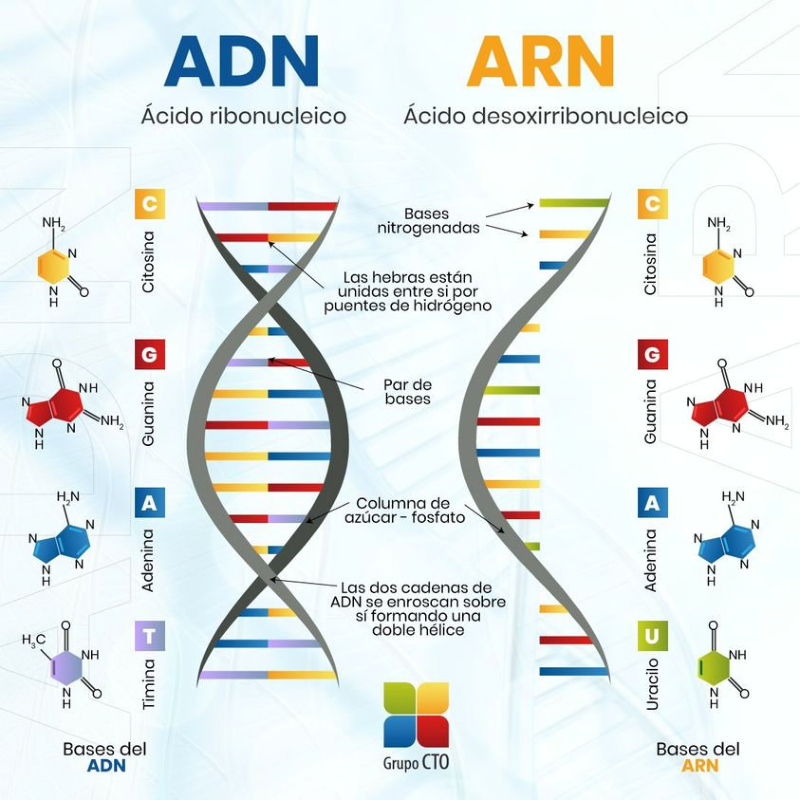
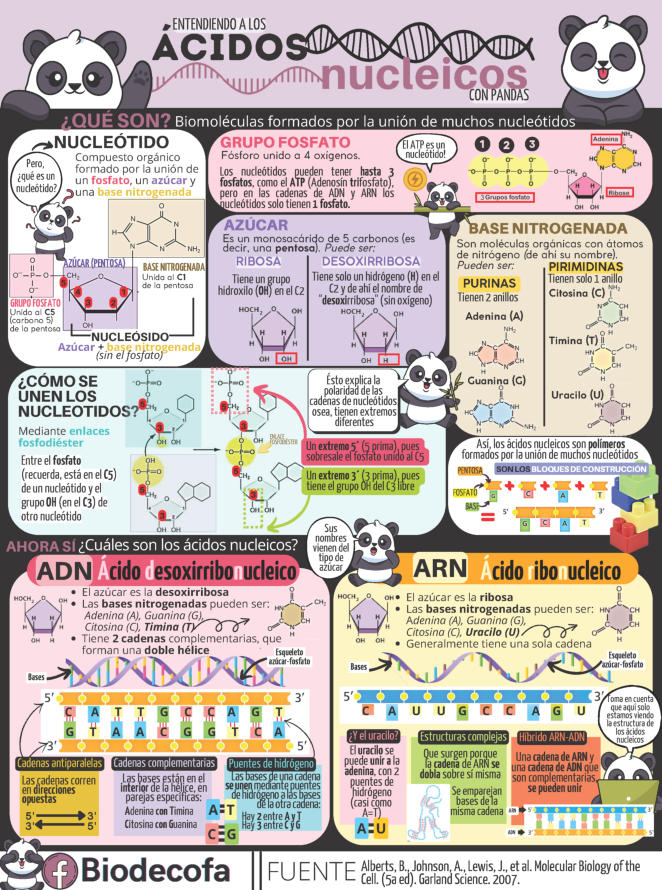
Los ácidos nucleicos son biomoléculas fibrilares gigantes, no ramificadas, que contienen la información genética. Esta información codificada permite llevar a cabo el metabolismo y los ciclos biológicos. Contienen la propia información en forma de genes y también las instrucciones para leerla. Son biopolímeros formados por monómeros llamados nucleótidos. Los nucleótidos, a su vez, son moléculas complejas, formadas por 3 componentes: Una molécula de ácido fosfórico (grupo fosfato). Un azúcar (pentosa) ciclada. Puede ser: β-D-ribosa, en el ARN. β-D-desoxirribosa, en el ADN. Una base nitrogenada. Molécula en forma de anillo con C y N. Hay dos tipos: Púricas: derivadas de la purina. Estructura con doble anillo. Son adenina (A) y guanina (G). Pirimidínicas: derivadas de la pirimidina. Con un único anillo. Son citosina (C), timina (T) y uracilo (U). 5.1.1. NUCLEÓSIDOS Los nucleósidos resultan de la unión de la pentosa (ribosa o desoxirribosa) y una base nitrogenada (púrica o pirimidínica). Existen 2 tipos de nucleósidos, cada uno con cuatro de las cinco bases posibles: Ribonucleósidos: contienen ribosa unida a A, G, C o U. Desoxirribonucleósidos: contienen desoxirribosa unida a A, G, C o T. La unión pentosa-base se realiza por un enlace N-glucosídico, con pérdida de agua, entre el –OH hemiacetálico del C 1’ de la pentosa y el hidrógeno del N 1 (base pirimidínica) o del N 9 (base púrica). Son adenosina, guanosina, citidina, uridina, desoxiadenosina, desoxiguanosina, desoxicitidina y desoxitimidina. 5.1.2. NUCLEÓTIDOS Los nucleótidos resultan de la unión, mediante enlace éster, de un grupo fosfato al C 5’ de la pentosa del nucleósido. Un nucleótido es un nucleósido fosforilado en posición 5’. Se nombran con el nombre del nucleósido o desoxinucleósido correspondiente + 5’-monofosfato: citidina-5’-monofosfato (CMP) o desoxitimidina-5’-monofosfato (dTMP). Tipos de nucleótidos y funciones que desempeñan Los nucleótidos pueden presentarse libres o unidos a otras moléculas. El grupo fosfato puede unirse a otros grupos, dando entre otros: Enlaces “ricos en energía” con otros grupos fosfato: nucleótidos difosfato y trifosfato (ADP, ATP). Transportan energía en sus enlaces, fácilmente hidrolizables. Un enlace éster intramolecular con el –OH en posición 3’, formando el AMP cíclico (AMP c ): que actúa como segundo mensajero entre moléculas extracelulares e intracelulares. Unión al grupo fosfato de otro nucleótido o de otra molécula, formando nucleótidos no nucleicos, que actúan como coenzimas. Coenzima Q, FAD (flavín adenín dinucleótido) y NAD + (nicotín adenín dinucleótido). Otro enlace éster con el –OH en posición 3’ de otro nucleótido, que se une a otro y así sucesivamente, dando cadenas de nucleótidos: ácidos nucleicos.5.2. ÁCIDO DESOXIRRIBONUCLEICO (ADN)
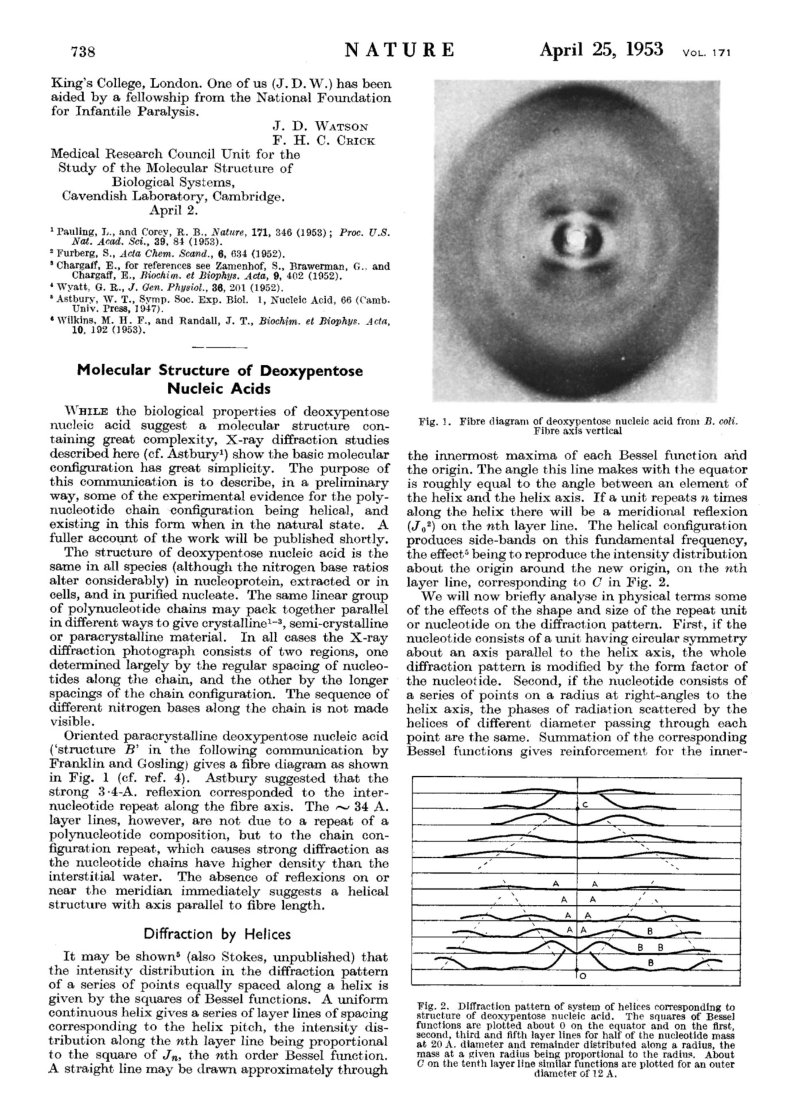
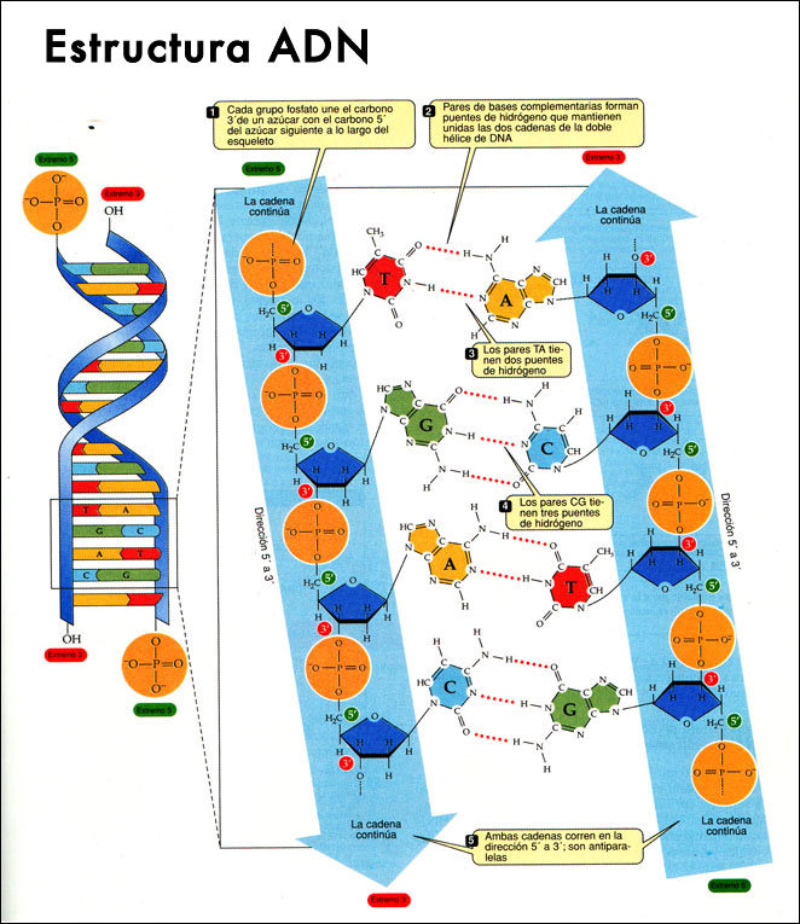
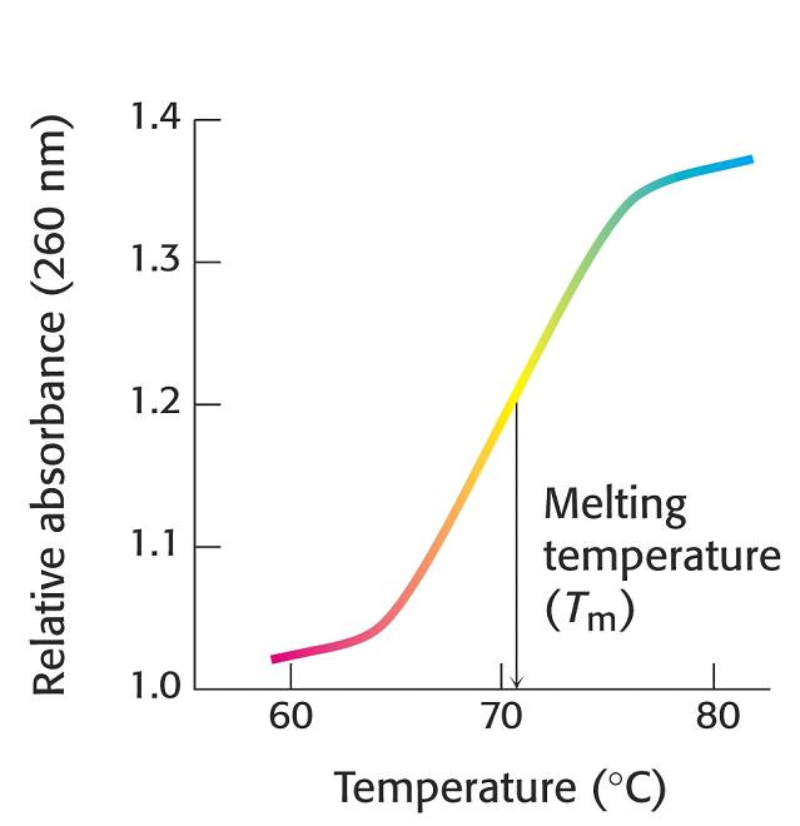
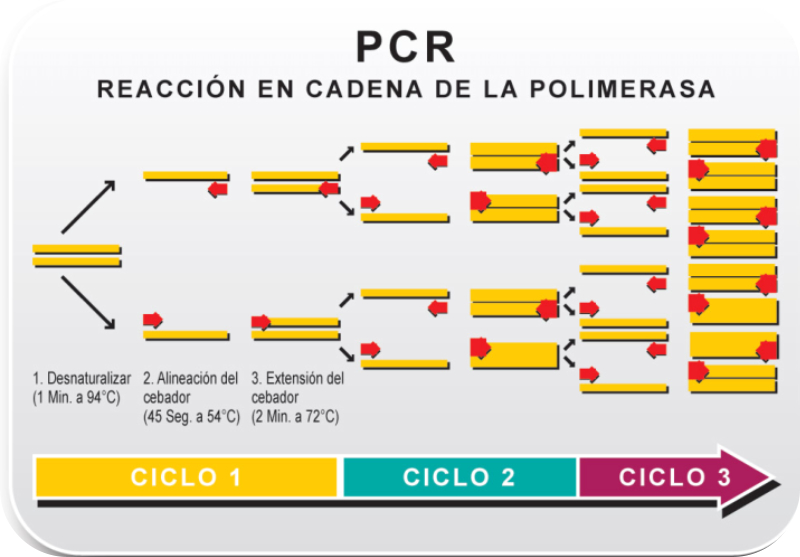
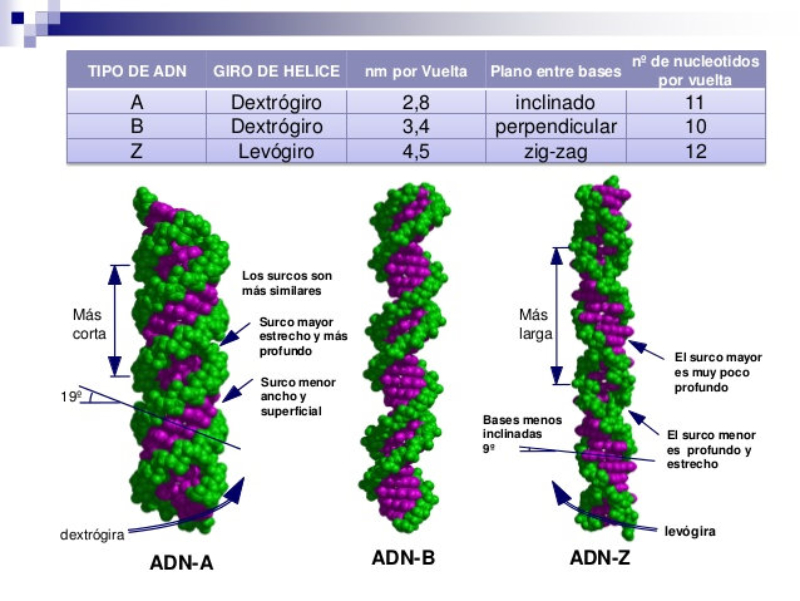
Biopolímero lineal de desoxirribonucleótidos-5’-monofosfato de A, G, C y T. En medio acuoso adopta una estructura tridimensional, pero sólo con conformación primaria y secundaria. 5.2.1. ESTRUCTURA 1 RIA Es la secuencia de desoxirribonucleótidos-5’-monofosfato. Las uniones se realizan por enlace éster: el grupo fosfato en posición 5’ de un nucleótido esterifica al –OH en el C 3’ del siguiente. La cadena transcurre en dirección 5’ 3’. El grupo fosfato forma un puente fosfodiéster entre dos desoxirribosas. Cada polinucleótido tiene dos partes: Un esqueleto de polidesoxirribosa-fosfato (… dRi-P-dRi-P-dRi-P- …), común para todos los ADN. Cada cadena tiene un extremo 5’ (inicio) con un fosfato libre unido al C 5’ de un nucleótido; y un extremo 3’ (final), con un –OH libre unido al C 3’ de otro nucleótido. Por convenio, se considera que el extremo 5’ es el comienzo de la cadena y el 3’ el final. La secuencia de bases nitrogenadas que diferencia unos ADN de otros. Como sucedía con las proteínas y los aa, cada molécula de ADN se diferencia en el número, tipo y secuencia de sus bases nitrogenadas. Esta secuencia contiene la información para la síntesis de proteínas. 5.2.2. ESTRUCTURA 2 RIA Es una doble hélice, formada por dos cadenas polinucleotídicas, enrolladas entre sí, enfrentadas por sus bases y unidas por puentes de H. El conjunto recuerda a una escalera de caracol, con el esqueleto de ribosa-fosfatos como pasamanos y las bases nitrogenadas como los peldaños de la escalera. Modelo de doble hélice de Watson y Crick: ADN-B En 1953 Watson y Crick presentaron en la revista Nature su modelo de estructura para el ADN. En 1962 recibirían el Premio Nobel por dicho descubrimiento, junto a Maurice Wilkins. El modelo propuesto por Watson y Crick presenta las siguientes características: Las cadenas son antiparalelas: una discurre en dirección 5’ 3’ y la otra en dirección 3’ 5’. Así, las bases quedan enfrentadas y pueden unirse. Las bases de cada cadena son complementarias. Hay una correspondencia entre las bases de cada cadena. Así, la adenina se une siempre a la timina, mediante 2 puentes de H; la citosina se une siempre a la guanina, mediante 3 puentes de H. Conociendo la secuencia de una cadena puede conocerse la de la otra. Siempre se enfrentan una base púrica y otra pirimidínica, de esa forma la doble hélice tiene siempre la misma anchura. El enrollamiento de las dos hélices es dextrógiro y plectonémico (trenzadas entre sí). 5.2.3. DESNATURALIZACIÓN DEL ADN La desnaturalización del ADN es la separación de las dos cadenas por rotura de los puentes de H, sin que se afecten los enlaces éster de cada cadena. Se produce por aumento de la temperatura, variación de pH o cambios iónicos. La desnaturalización por temperatura se denomina fusión. Se llama punto de fusión (T m ) a la temperatura en que la mitad de las moléculas de ADN están desnaturalizadas. La desnaturalización es reversible. Recobradas las condiciones necesarias, si dos cadenas son total o parcialmente complementarias, volverán a unirse (renaturalización). La desnaturalización y renaturalización han dado lugar a técnicas de ingeniería genética o biotecnología, como la hibridación, tecnologías del ADN recombinante, PCR, etc. La hibridación de cadenas no naturales ADN-ADN o ADN-ARN permite comprobar el grado de relación entre dos cadenas, lo que puede usarse para estudiar relaciones filogenéticas, de parentesco o de reconocimiento de secuencias.5.3.
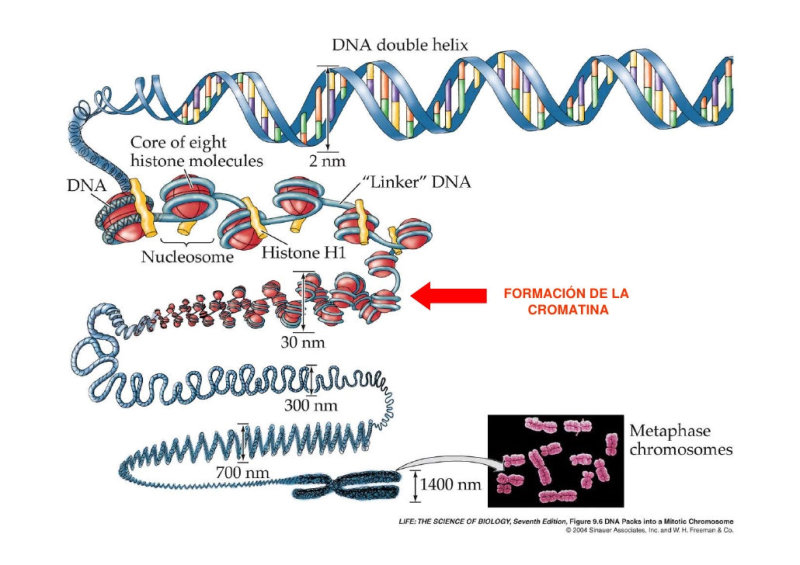
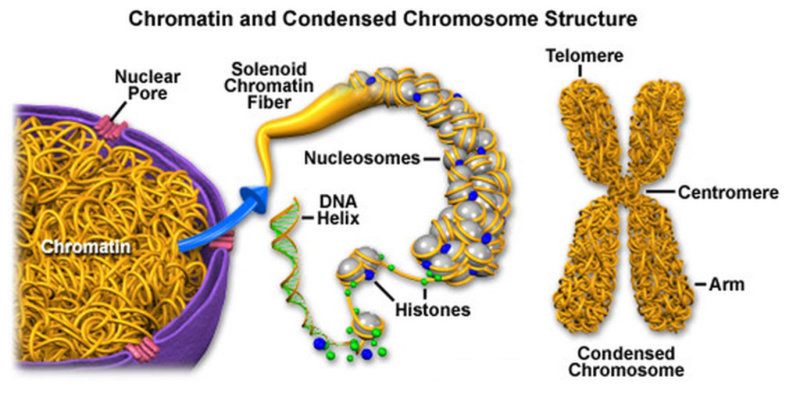
OTROS NIVELES DE COMPLEJIDAD DEL ADN
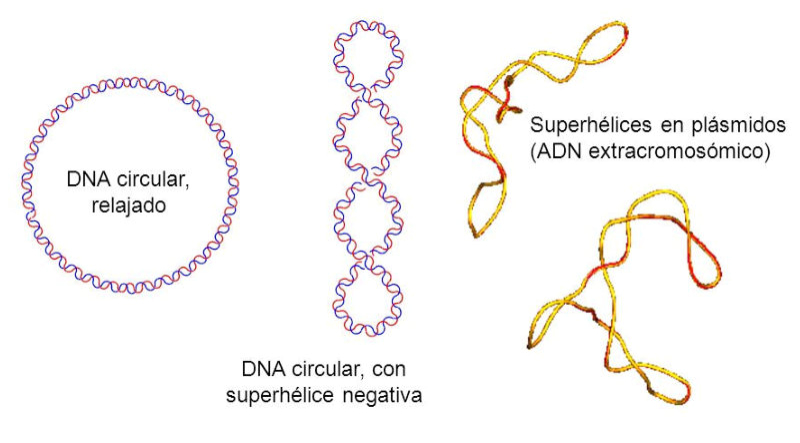
Aunque el ADN sólo alcanza un nivel de complejidad de estructura secundaria, unido a proteínas puede alcanzar otros niveles de complejidad muy elevada. Así, en procariotas, el ADN, que es una doble cadena circular, se une a unas pocas proteínas y se enrolla en una superhélice en forma de ochos. En eucariotas el problema es mayor, ya que hay numerosas cadenas de ADN y mucha mayor cantidad. Para plegarse, se une a un gran número de proteínas llamadas histonas (junto a protaminas en los espermatozoides). La forma compacta así adquirida se denomina cromatina, que es una estructura muy compleja y ordenada. Durante la división celular, la cromatina se empaqueta aún más, formando los cromosomas.5.4.
ÁCIDO RIBONUCLEICO (ARN)
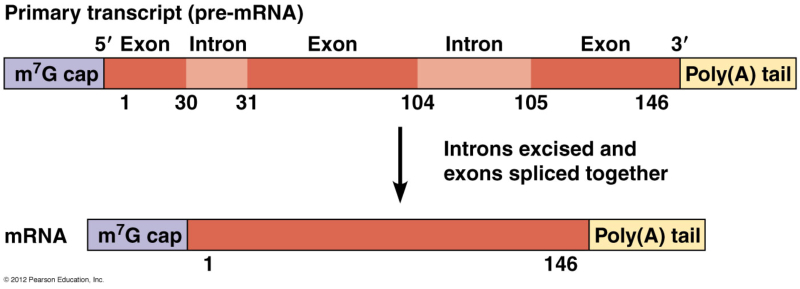
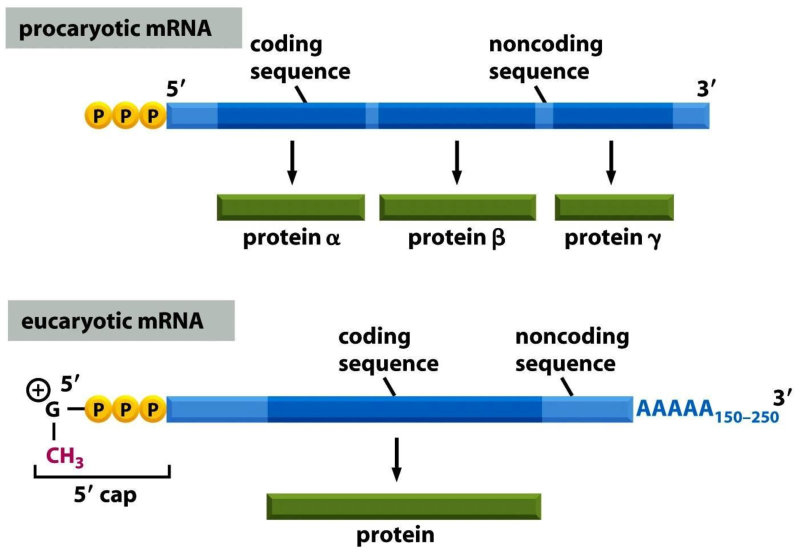
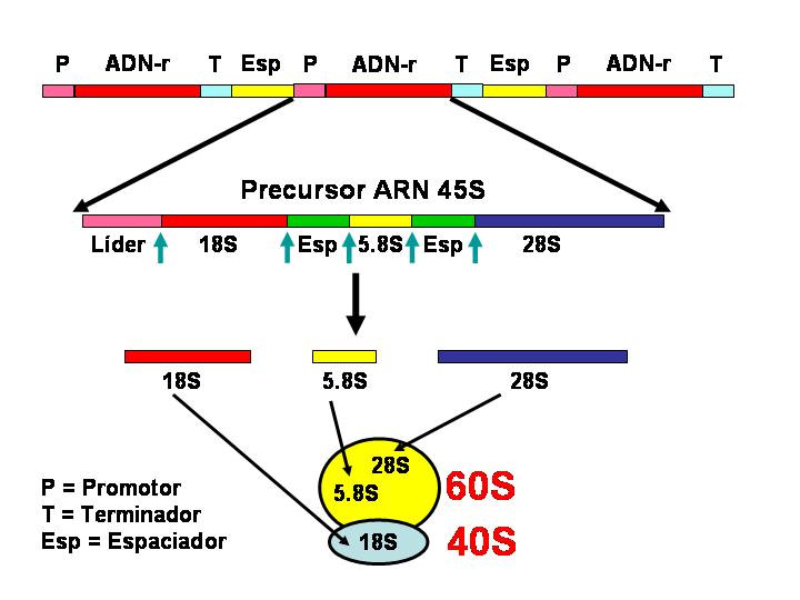
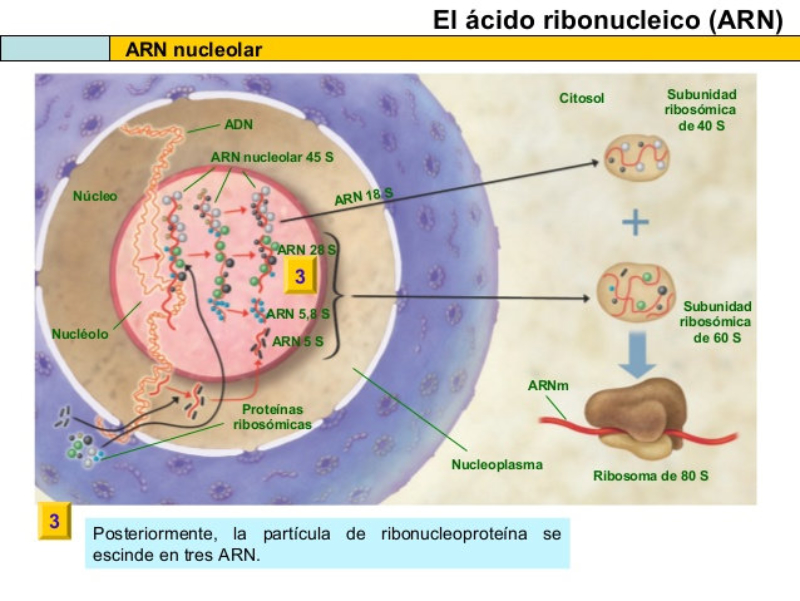
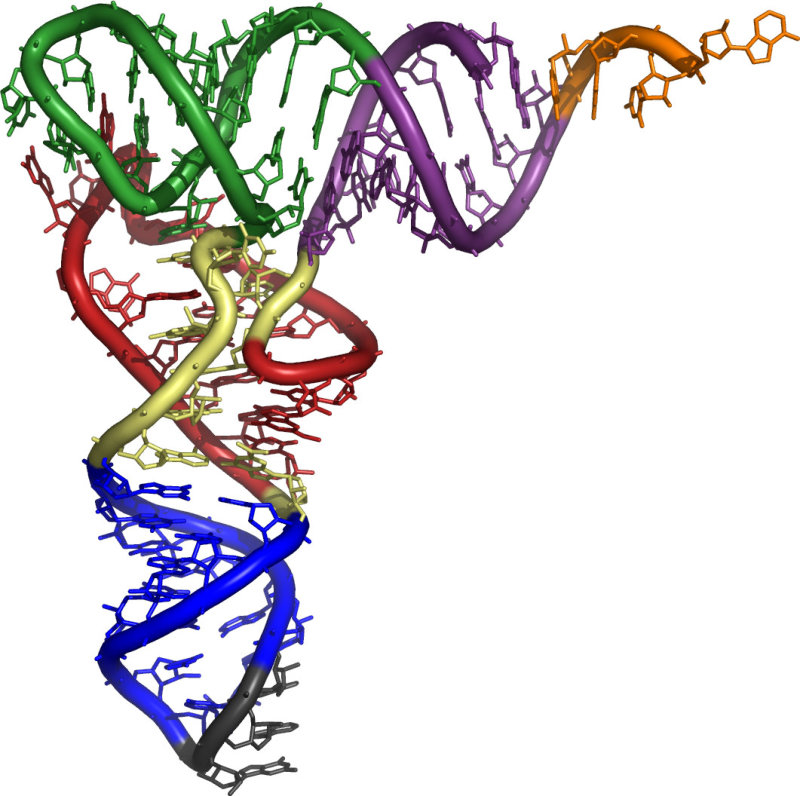
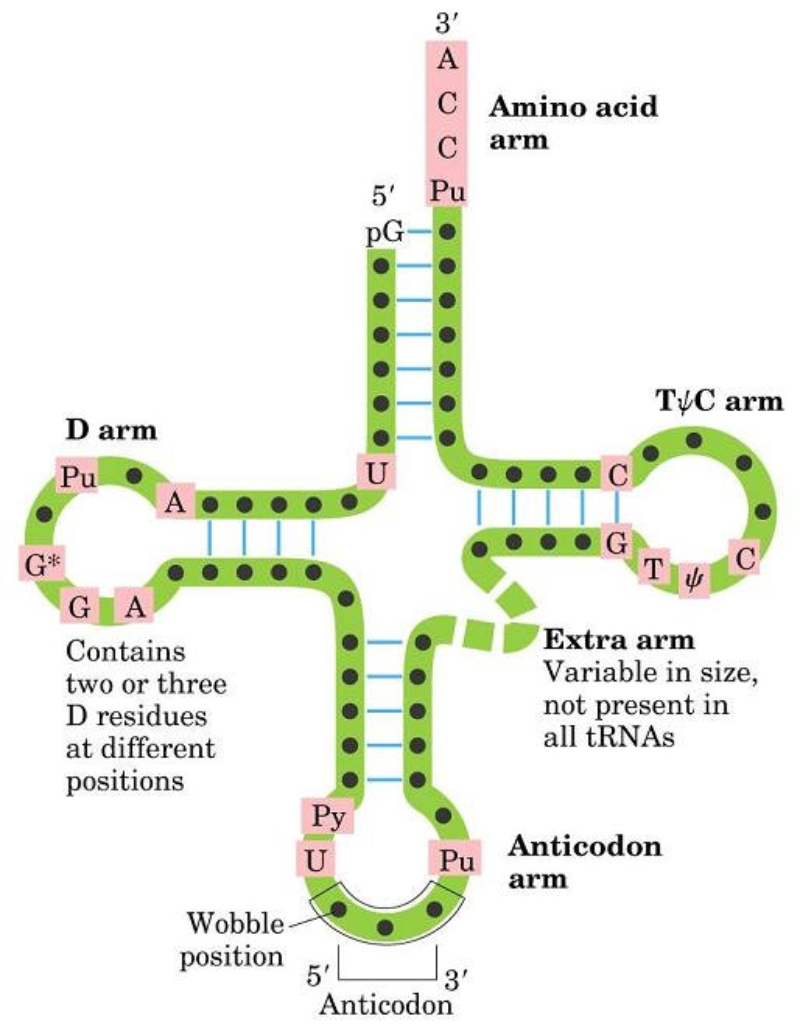
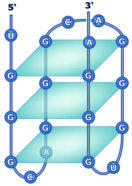
Biopolímero lineal de ribonucleótidos-5’-monofosfato. Su estructura primaria es idéntica a la del ADN, con uniones fosfodiéster 5’-3’ de ribonucleótidos. Sin embargo, ARN y ADN presentan las siguientes diferencias: El ARN lleva ribosa y el ADN, desoxirribosa. La presencia del grupo –OH libre en los ribonucleótidos crea tensiones que hacen del ARN una molécula menos estable que el ADN. El ARN lleva la base U, en lugar de T, frente a la A. En algunos ARN (ARN t ) existen otros compuestos nitrogenados: pseudouracilo (ψ), dimetilguanina, hipoxantina, etc. El ARN suele tener sólo estructura primaria, aunque en ciertas regiones de la cadena puede aparecer complementariedad de las bases y formar una doble cadena (doble hélice). Sólo se conoce ARN bicatenario en un tipo de virus, los reovirus. El ARN constituye el genoma de ciertos virus. Algunos ARN tienen actividad catalítica, es decir, son enzimas llamados ribozimas. En los años 90 del siglo pasado se encontraron cadenas de ARN llamadas ARN de interferencia (ARN i ), de sólo 20-25 nucleótidos, con un papel muy importante en el desarrollo y diferenciación celular, control de la expresión génica y defensa contra virus. Para clasificar los ARN suele usarse su masa molecular Se mide de forma indirecta mediante el coeficiente de sedimentación (velocidad a la que sedimentan las moléculas sometidas a centrifugación). El coeficiente de sedimentación se mide en unidades Svedberg (S). 5.4.1. ARN MENSAJERO (ARN M ) Es una larga cadena polinucleotídica, de longitud variable, con estructura primaria. Filamento que lleva información para sintetizar una cadena polipeptídica. Existe una correspondencia entre la secuencia de bases del ARN m y la secuencia de aa de la proteína: el código genético. El ARN m es diferente en procariotas y eucariotas: Procariotas: poseen en el extremo 5’ un grupo trifosfato. Eucariotas: en el extremo 5’ llevan una especie de caperuza (CAP) consistente en metil guanosina unida a un trifosfato. En el extremo 3’ llevan una cola llamada cola de poli A por estar formada por unos 150-200 nucleótidos de A. Los ARN m eucariotas, además, contienen secuencias de bases codificantes de proteínas (exones) intercalados con otros no codificantes (intrones). La información genética aparece fragmentada y el ARN m debe pasar un proceso de maduración para dar un ARN m funcional. Estos ARN m sólo duran unos minutos antes de degradarse. 5.4.2. ARN NUCLEOLAR (ARN N ) ARN de elevado peso molecular (45 S), con estructura terciaria en algunas regiones. Se sintetiza en el nucleolo y es un precursor de diferentes ARN r , que formarán las subunidades del ribosoma. 5.4.3. ARN RIBOSÓMICO (ARN R ) Moléculas de tamaño variable, con estructura 2 ria y 3 ria en algunas regiones. Se unen a más de 60 proteínas para formar los ribosomas. En procariotas existen 3 tipos: 23S, 16S y 5S. En eucariotas son 4: 28S, 18S, 5’8S y 5S. Los diferentes ARN r le dan a los ribosomas la estructura apropiada para albergar al ARN m (subunidad pequeña) y a los aa unidos a ARN t (subunidad grande) para la síntesis de proteínas. Los ARN r 23S de procariotas y 28S en eucariotas son ribozimas, enzimas catalíticos que forman el enlace peptídico durante la síntesis proteica. 4.4. ARN DE TRANSFERENCIA (ARN T ) Moléculas pequeñas (80-100 nucleótidos), con estructura 2 ria y 3 ria , que llevan los aa hasta los ribosomas para la síntesis proteica. Cada ARN t (existen unos 31) tiene regiones con bases complementarias, que se emparejan y adquieren estructura de doble hélice. Las regiones no apareadas aparecen como bucles. En conjunto, la apariencia de la molécula plana es la de una hoja de trébol, pero con una estructura 3 ria con forma de L o bumerán. La estructura 2 ria del ARN t consta de: Un brazo aceptor: formado por el extremo 5’ (G-P) y el 3’ con la secuencia CCA cuyo –OH terminal servirá de unión al aa correspondiente. Un bucle o brazo TψC (TpsiC) (o brazo T): lugar de reconocimiento del ribosoma. + Un bucle o brazo D: con una secuencia reconocida específicamente por una de las 20 enzimas aminoacil-ARN t sintetasas, que unen cada aa a su ARNt correspondiente. El brazo anticodón, un bucle situado en el extremo del brazo largo. Contiene una secuencia de 3 bases llamada anticodón, que se une específicamente a tripletes (3 bases) complementarias del ARN m que se lee en el ribosoma. Los ARN t tienen un 10% de bases que son modificaciones de las 4 habituales (A, G, C y U), como el pseudouracilo (ψ).5.5.
FUNCIONES BIOLÓGICAS DE LOS ÁCIDOS
NUCLEICOS
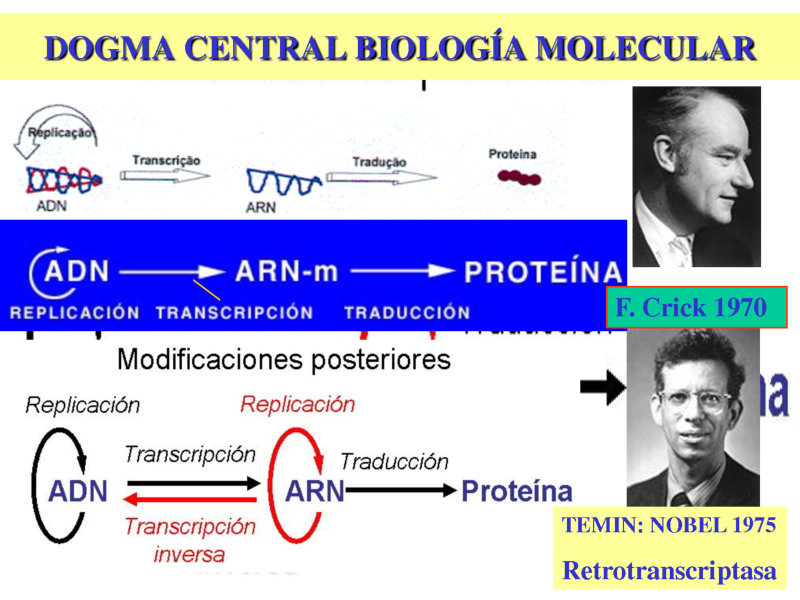
Replicación: el ADN se replica o duplica, haciendo copias de sí mismo. Se libera de las histonas, se abre separando las dos cadenas y se sintetiza la complementaria de cada una. Así se forman dos copias idénticas para repartir a las células hijas en la división celular, pasando la información genética de generación en generación. Almacenamiento de la información genética: contiene, en lenguaje químico (secuencia de bases) la información necesaria para sintetizar todas las proteínas de un organismo. Transcripción: la información del ADN se transcribe al ARN m , gracias a la complementariedad de bases A=U y G≡C. Traducción: el mensaje del ADN se convierte en proteínas. Los ribosomas leen el ARN m y fabrican una proteína con ayuda del ARN t que aporta los aa.
















































Para ir a donde no se sabe hay que ir por donde no se sabe.” San Juan de la Cruz
“It must be a strange world not being a scientist, going through life not knowing--or
maybe not caring about where the air came from, where the stars at night came from or
how far they are from us. I WANT TO KNOW” Michio Kaku
“Nullius in verba” Robert Boyle, Christopher Wren y Robert Hooke






































¿Qué ves aquí?

Un mosaico hecho de diferentes colores de granos de maíz que
representa el ADN. La mayoría de los granos se cultivaron en un campo
de investigación de Cornell en el verano de 2012.
Comenzando en la esquina superior izquierda, la secuencia completa
es GCTTCAGAGA, que forma parte del exón 6 del gen r1 del maíz, uno
de los genes clásicos que controla el color del grano de maíz.
El código de color es: Verde = Guanina (G); Naranja = Citosina (C); Azul
= Timina (T);Blanco = Adenina (A)


4.000 personas hicieron la caderna de ADN más grande del mundo en una playa de Varna (Bulgaria) en abril de 2016



")
")


















![[x]](bg2bto_htm_files/close.png "Close")